Which finds the widest application in various fields of science and practice. It can be physics, chemistry, biology, economics, sociology, psychology and so on and so forth. By the will of fate, I often have to deal with the economy, and therefore today I will arrange for you a ticket to an amazing country called Econometrics=) … How do you not want that?! It's very good there - you just have to decide! …But what you probably definitely want is to learn how to solve problems least squares. And especially diligent readers will learn to solve them not only accurately, but also VERY FAST ;-) But first general statement of the problem+ related example:
Let indicators be studied in some subject area that have a quantitative expression. At the same time, there is every reason to believe that the indicator depends on the indicator. This assumption can be scientific hypothesis and be based on elementary common sense. Let's leave science aside, however, and explore more appetizing areas - namely, grocery stores. Denote by:
– retail space of a grocery store, sq.m.,
- annual turnover of a grocery store, million rubles.
It is quite clear that the larger the area of the store, the greater its turnover in most cases.
Suppose that after conducting observations / experiments / calculations / dancing with a tambourine, we have at our disposal numerical data: 
With grocery stores, I think everything is clear: - this is the area of the 1st store, - its annual turnover, - the area of the 2nd store, - its annual turnover, etc. By the way, it is not at all necessary to have access to classified materials - a fairly accurate assessment of the turnover can be obtained using mathematical statistics. However, do not be distracted, the course of commercial espionage is already paid =)
Tabular data can also be written in the form of points and depicted in the usual way for us. Cartesian system .
Let's answer an important question: how many points are needed for a qualitative study?
The bigger, the better. The minimum admissible set consists of 5-6 points. In addition, with a small amount of data, “abnormal” results should not be included in the sample. So, for example, a small elite store can help out orders of magnitude more than “their colleagues”, thereby distorting the general pattern that needs to be found!
If it’s quite simple, we need to choose a function , schedule which passes as close as possible to the points ![]() . Such a function is called approximating
(approximation - approximation) or theoretical function
. Generally speaking, here immediately appears an obvious "pretender" - a polynomial of high degree, the graph of which passes through ALL points. But this option is complicated, and often simply incorrect. (because the chart will “wind” all the time and poorly reflect the main trend).
. Such a function is called approximating
(approximation - approximation) or theoretical function
. Generally speaking, here immediately appears an obvious "pretender" - a polynomial of high degree, the graph of which passes through ALL points. But this option is complicated, and often simply incorrect. (because the chart will “wind” all the time and poorly reflect the main trend).
Thus, the desired function must be sufficiently simple and at the same time reflect the dependence adequately. As you might guess, one of the methods for finding such functions is called least squares. First, let's analyze its essence in a general way. Let some function approximate the experimental data: 
How to evaluate the accuracy of this approximation? Let us also calculate the differences (deviations) between the experimental and functional values (we study the drawing). The first thought that comes to mind is to estimate how big the sum is, but the problem is that the differences can be negative. (for example, ![]() )
and deviations as a result of such summation will cancel each other out. Therefore, as an estimate of the accuracy of the approximation, it suggests itself to take the sum modules deviations:
)
and deviations as a result of such summation will cancel each other out. Therefore, as an estimate of the accuracy of the approximation, it suggests itself to take the sum modules deviations:
![]() or in folded form: (suddenly, who doesn’t know: is the sum icon, and is an auxiliary variable-“counter”, which takes values from 1 to ).
or in folded form: (suddenly, who doesn’t know: is the sum icon, and is an auxiliary variable-“counter”, which takes values from 1 to ).
Approximating the experimental points with various functions, we will obtain different meanings, and obviously, where this sum is less, that function is more accurate.
Such a method exists and is called least modulus method. However, in practice it has become much more widespread. least square method, in which possible negative values are eliminated not by the modulus, but by squaring the deviations:
![]() , after which efforts are directed to the selection of such a function that the sum of the squared deviations
, after which efforts are directed to the selection of such a function that the sum of the squared deviations ![]() was as small as possible. Actually, hence the name of the method.
was as small as possible. Actually, hence the name of the method.
And now we return to another important point: as noted above, the selected function should be quite simple - but there are also many such functions: linear , hyperbolic, exponential, logarithmic, quadratic etc. And, of course, here I would immediately like to "reduce the field of activity." What class of functions to choose for research? Primitive but effective technique:
- The easiest way to draw points ![]() on the drawing and analyze their location. If they tend to be in a straight line, then you should look for straight line equation
on the drawing and analyze their location. If they tend to be in a straight line, then you should look for straight line equation ![]() with optimal values and . In other words, the task is to find SUCH coefficients - so that the sum of the squared deviations is the smallest.
with optimal values and . In other words, the task is to find SUCH coefficients - so that the sum of the squared deviations is the smallest.
If the points are located, for example, along hyperbole, then it is clear that the linear function will give a poor approximation. In this case, we are looking for the most “favorable” coefficients for the hyperbola equation ![]() - those that give the minimum sum of squares
- those that give the minimum sum of squares  .
.
Now notice that in both cases we are talking about functions of two variables, whose arguments are searched dependency options:
And in essence, we need to solve a standard problem - to find minimum of a function of two variables.
Recall our example: suppose that the "shop" points tend to be located in a straight line and there is every reason to believe the presence linear dependence turnover from the trading area. Let's find SUCH coefficients "a" and "be" so that the sum of squared deviations ![]() was the smallest. Everything as usual - first partial derivatives of the 1st order. According to linearity rule you can differentiate right under the sum icon:
was the smallest. Everything as usual - first partial derivatives of the 1st order. According to linearity rule you can differentiate right under the sum icon: 
If you want to use this information for an essay or a term paper, I will be very grateful for the link in the list of sources, you will not find such detailed calculations anywhere: 
Let's make a standard system: 
We reduce each equation by a “two” and, in addition, “break apart” the sums: 
Note
: independently analyze why "a" and "be" can be taken out of the sum icon. By the way, formally this can be done with the sum![]()
Let's rewrite the system in an "applied" form: 
after which the algorithm for solving our problem begins to be drawn:
Do we know the coordinates of the points? We know. Sums ![]() can we find? Easily. We compose the simplest system of two linear equations with two unknowns("a" and "beh"). We solve the system, for example, Cramer's method, resulting in a stationary point . Checking sufficient condition for an extremum, we can verify that at this point the function
can we find? Easily. We compose the simplest system of two linear equations with two unknowns("a" and "beh"). We solve the system, for example, Cramer's method, resulting in a stationary point . Checking sufficient condition for an extremum, we can verify that at this point the function ![]() reaches precisely minimum. Verification is associated with additional calculations and therefore we will leave it behind the scenes. (if necessary, the missing frame can be viewed). We draw the final conclusion:
reaches precisely minimum. Verification is associated with additional calculations and therefore we will leave it behind the scenes. (if necessary, the missing frame can be viewed). We draw the final conclusion:
Function ![]() the best way (at least compared to any other linear function) brings experimental points closer
the best way (at least compared to any other linear function) brings experimental points closer ![]() . Roughly speaking, its graph passes as close as possible to these points. In tradition econometrics the resulting approximating function is also called paired linear regression equation
.
. Roughly speaking, its graph passes as close as possible to these points. In tradition econometrics the resulting approximating function is also called paired linear regression equation
.
The problem under consideration is of great practical importance. In the situation with our example, the equation ![]() allows you to predict what kind of turnover ("yig") will be at the store with one or another value of the selling area (one or another meaning of "x"). Yes, the resulting forecast will be only a forecast, but in many cases it will turn out to be quite accurate.
allows you to predict what kind of turnover ("yig") will be at the store with one or another value of the selling area (one or another meaning of "x"). Yes, the resulting forecast will be only a forecast, but in many cases it will turn out to be quite accurate.
I will analyze just one problem with "real" numbers, since there are no difficulties in it - all calculations are at the level of the school curriculum in grades 7-8. In 95 percent of cases, you will be asked to find just a linear function, but at the very end of the article I will show that it is no more difficult to find the equations for the optimal hyperbola, exponent, and some other functions.
In fact, it remains to distribute the promised goodies - so that you learn how to solve such examples not only accurately, but also quickly. We carefully study the standard:
A task
As a result of studying the relationship between two indicators, the following pairs of numbers were obtained: 
Using the least squares method, find the linear function that best approximates the empirical (experienced) data. Make a drawing on which, in a Cartesian rectangular coordinate system, plot experimental points and a graph of the approximating function ![]() . Find the sum of squared deviations between empirical and theoretical values. Find out if the function is better (in terms of the least squares method) approximate experimental points.
. Find the sum of squared deviations between empirical and theoretical values. Find out if the function is better (in terms of the least squares method) approximate experimental points.
Note that "x" values are natural values, and this has a characteristic meaningful meaning, which I will talk about a little later; but they, of course, can be fractional. In addition, depending on the content of a particular task, both "X" and "G" values can be fully or partially negative. Well, we have been given a “faceless” task, and we start it solution:
We find the coefficients of the optimal function as a solution to the system: 
For the purposes of a more compact notation, the “counter” variable can be omitted, since it is already clear that the summation is carried out from 1 to .
It is more convenient to calculate the required amounts in a tabular form: 
Calculations can be carried out on a microcalculator, but it is much better to use Excel - both faster and without errors; watch a short video:
Thus, we get the following system:![]()
Here you can multiply the second equation by 3 and subtract the 2nd from the 1st equation term by term. But this is luck - in practice, systems are often not gifted, and in such cases it saves Cramer's method:
, so the system has a unique solution.

Let's do a check. I understand that I don’t want to, but why skip mistakes where you can absolutely not miss them? Substitute the found solution into the left side of each equation of the system:
The right parts of the corresponding equations are obtained, which means that the system is solved correctly.
Thus, the desired approximating function: – from all linear functions experimental data is best approximated by it.
Unlike straight
dependence of the store's turnover on its area, the found dependence is reverse
(principle "the more - the less"), and this fact is immediately revealed by the negative angular coefficient. Function ![]() informs us that with an increase in a certain indicator by 1 unit, the value of the dependent indicator decreases average by 0.65 units. As they say, the higher the price of buckwheat, the less sold.
informs us that with an increase in a certain indicator by 1 unit, the value of the dependent indicator decreases average by 0.65 units. As they say, the higher the price of buckwheat, the less sold.
To plot the approximating function, we find two of its values:
and execute the drawing: 
The constructed line is called trend line
(namely, a linear trend line, i.e. in the general case, a trend is not necessarily a straight line). Everyone is familiar with the expression "to be in trend", and I think that this term does not need additional comments.
Calculate the sum of squared deviations ![]() between empirical and theoretical values. Geometrically, this is the sum of the squares of the lengths of the "crimson" segments (two of which are so small you can't even see them).
between empirical and theoretical values. Geometrically, this is the sum of the squares of the lengths of the "crimson" segments (two of which are so small you can't even see them).
Let's summarize the calculations in a table: 
They can again be carried out manually, just in case I will give an example for the 1st point: ![]()
but it is much more efficient to do the already known way:
Let's repeat: what is the meaning of the result? From all linear functions function ![]() the exponent is the smallest, that is, it is the best approximation in its family. And here, by the way, the final question of the problem is not accidental: what if the proposed exponential function
the exponent is the smallest, that is, it is the best approximation in its family. And here, by the way, the final question of the problem is not accidental: what if the proposed exponential function ![]() will it be better to approximate the experimental points?
will it be better to approximate the experimental points?
Let's find the corresponding sum of squared deviations - to distinguish them, I will designate them with the letter "epsilon". The technique is exactly the same: 
And again for every fire calculation for the 1st point: 
In Excel, we use the standard function EXP (Syntax can be found in Excel Help).
Conclusion: , so the exponential function approximates the experimental points worse than the straight line ![]() .
.
But it should be noted here that "worse" is doesn't mean yet, what is wrong. Now I built a graph of this exponential function - and it also passes close to the points ![]() - so much so that without an analytical study it is difficult to say which function is more accurate.
- so much so that without an analytical study it is difficult to say which function is more accurate.
This completes the solution, and I return to the question of the natural values of the argument. In various studies, as a rule, economic or sociological, months, years or other equal time intervals are numbered with natural "X". Consider, for example, such a problem.
Least square method is used to estimate the parameters of the regression equation.One of the methods for studying stochastic relationships between features is regression analysis.
Regression analysis is the derivation of a regression equation, which is used to find average value a random variable (feature-result), if the value of another (or other) variables (feature-factors) is known. It includes the following steps:
- choice of the form of connection (type of analytical regression equation);
- estimation of equation parameters;
- evaluation of the quality of the analytical regression equation.
In the case of a linear pair relationship, the regression equation will take the form: y i =a+b·x i +u i . The parameters of this equation a and b are estimated from the data of statistical observation x and y . The result of such an assessment is the equation: , where , - estimates of the parameters a and b , - the value of the effective feature (variable) obtained by the regression equation (calculated value).
The most commonly used for parameter estimation is least squares method (LSM).
The least squares method gives the best (consistent, efficient and unbiased) estimates of the parameters of the regression equation. But only if certain assumptions about the random term (u) and the independent variable (x) are met (see OLS assumptions).
The problem of estimating the parameters of a linear pair equation by the least squares method consists in the following: to obtain such estimates of the parameters , , at which the sum of the squared deviations of the actual values of the effective feature - y i from the calculated values - is minimal.
Formally OLS criterion can be written like this:  .
.
Classification of least squares methods
- Least square method.
- Maximum likelihood method (for a normal classical linear regression model, normality of regression residuals is postulated).
- The generalized least squares method of GLSM is used in the case of error autocorrelation and in the case of heteroscedasticity.
- Weighted least squares method (a special case of GLSM with heteroscedastic residuals).
Illustrate the essence the classical method of least squares graphically. To do this, we will build a dot plot according to the observational data (x i , y i , i=1;n) in a rectangular coordinate system (such a dot plot is called a correlation field). Let's try to find a straight line that is closest to the points of the correlation field. According to the least squares method, the line is chosen so that the sum of squared vertical distances between the points of the correlation field and this line would be minimal. 
Mathematical notation of this problem:  .
.
The values of y i and x i =1...n are known to us, these are observational data. In the function S they are constants. The variables in this function are the required estimates of the parameters - , . To find the minimum of a function of 2 variables, it is necessary to calculate the partial derivatives of this function with respect to each of the parameters and equate them to zero, i.e.  .
.
As a result, we obtain a system of 2 normal linear equations: 
Solving this system, we find the required parameter estimates: 
The correctness of the calculation of the parameters of the regression equation can be checked by comparing the sums (some discrepancy is possible due to rounding of the calculations).
To calculate parameter estimates , you can build Table 1.
The sign of the regression coefficient b indicates the direction of the relationship (if b > 0, the relationship is direct, if b<0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
Formally, the value of the parameter a is the average value of y for x equal to zero. If the sign-factor does not have and cannot have a zero value, then the above interpretation of the parameter a does not make sense.
Assessment of the tightness of the relationship between features
is carried out using the coefficient of linear pair correlation - r x,y . It can be calculated using the formula:  . In addition, the coefficient of linear pair correlation can be determined in terms of the regression coefficient b:
. In addition, the coefficient of linear pair correlation can be determined in terms of the regression coefficient b:  .
.
The range of admissible values of the linear coefficient of pair correlation is from –1 to +1. The sign of the correlation coefficient indicates the direction of the relationship. If r x, y >0, then the connection is direct; if r x, y<0, то связь обратная.
If this coefficient is close to unity in modulus, then the relationship between the features can be interpreted as a fairly close linear one. If its modulus is equal to one ê r x , y ê =1, then the relationship between the features is functional linear. If features x and y are linearly independent, then r x,y is close to 0.
Table 1 can also be used to calculate r x,y.
To assess the quality of the obtained regression equation, the theoretical coefficient of determination is calculated - R 2 yx:  ,
,
where d 2 is the variance y explained by the regression equation;
e 2 - residual (unexplained by the regression equation) variance y ;
s 2 y - total (total) variance y .
The coefficient of determination characterizes the share of variation (dispersion) of the resulting feature y, explained by regression (and, consequently, the factor x), in the total variation (dispersion) y. The coefficient of determination R 2 yx takes values from 0 to 1. Accordingly, the value 1-R 2 yx characterizes the proportion of variance y caused by the influence of other factors not taken into account in the model and specification errors.
With paired linear regression R 2 yx =r 2 yx .
4.1. Using built-in functions
calculation regression coefficients carried out using the function
LINEST(Values_y; Values_x; Konst; statistics),
Values_y- array of y values,
Values_x- optional array of values x if array X omitted, it is assumed that this is an array (1;2;3;...) of the same size as Values_y,
Konst- a boolean value that indicates whether the constant is required b was equal to 0. If Konst has the meaning TRUE or omitted, then b calculated in the usual way. If the argument Konst is FALSE, then b is assumed to be 0 and the values a are chosen so that the relation y=ax.
Statistics- a boolean value that indicates whether additional regression statistics are required to be returned. If the argument Statistics has the meaning TRUE, then the function LINEST returns additional regression statistics. If the argument Statistics has the meaning FALSE or omitted, then the function LINEST returns only the coefficient a and permanent b.
It must be remembered that the result of the functions LINEST() is a set of values - an array.
For calculation correlation coefficient function is used
CORREL(Array1;Array2),
returning the values of the correlation coefficient, where Array1- array of values y, Array2- array of values x. Array1 and Array2 must be the same size.
EXAMPLE 1. Addiction y(x) is presented in the table. Build regression line and calculate correlation coefficient.
| y | 0.5 | 1.5 | 2.5 | 3.5 | |||||
| x | 2.39 | 2.81 | 3.25 | 3.75 | 4.11 | 4.45 | 4.85 | 5.25 |
Let's enter a table of values into MS Excel sheet and build a scatter plot. The worksheet will take the form shown in Fig. 2.
In order to calculate the values of the regression coefficients a and b select cells A7:B7, let's turn to the function wizard and in the category Statistical choose a function LINEST. Fill in the dialog box that appears as shown in Fig. 3 and press OK.
As a result, the calculated value will appear only in the cell A6(Fig. 4). For a value to appear in a cell B6 you need to enter edit mode (key F2) and then press the key combination CTRL+SHIFT+ENTER.
To calculate the value of the correlation coefficient per cell C6 the following formula was introduced:
C7=CORREL(B3:J3;B2:J2).
Knowing the regression coefficients a and b calculate the values of the function y=ax+b for given x. To do this, we introduce the formula
B5=$A$7*B2+$B$7
and copy it to the range С5:J5(Fig. 5).
Let's plot the regression line on the diagram. Select the experimental points on the chart, right-click and select the command Initial data. In the dialog box that appears (Fig. 5), select the tab Row and click on the button Add. Fill in the input fields, as shown in Fig. 6 and press the button OK. A regression line will be added to the experimental data plot. By default, its graph will be displayed as dots not connected by smoothing lines.
To change the appearance of the regression line, perform the following steps. Right-click on the points depicting the line graph, select the command Chart type and set the type of scatter plot, as shown in Fig. 7.
The line type, color and thickness can be changed as follows. Select the line on the diagram, press the right mouse button and select the command in the context menu Data Series Format… Next, make settings, for example, as shown in Fig. eight.
As a result of all the transformations, we get a graph of experimental data and a regression line in one graphic area (Fig. 9).
4.2. Using a trend line.
The construction of various approximating dependencies in MS Excel is implemented as a chart property - trend line.
EXAMPLE 2. As a result of the experiment, some tabular dependence was determined.
| 0.15 | 0.16 | 0.17 | 0.18 | 0.19 | 0.20 |
| 4.4817 | 4.4930 | 5.4739 | 6.0496 | 6.6859 | 7.3891 |
Select and build an approximating dependence. Build graphs of tabular and fitted analytical dependencies.
The solution of the problem can be divided into the following stages: input of initial data, construction of a scatter plot and addition of a trend line to this plot.
Let's consider this process in detail. Let's enter the initial data into the worksheet and plot the experimental data. Next, select the experimental points on the chart, right-click and use the command Add l trend line(Fig. 10).
The dialog box that appears allows you to build an approximating dependence.
The first tab (Fig. 11) of this window indicates the type of approximating dependence.
The second one (Fig. 12) defines the construction parameters:
the name of the approximating dependence;
Forecast forward (backward) on n units (this parameter determines how many units forward (backward) it is necessary to extend the trend line);
whether to show the point of intersection of the curve with the line y=const;
whether to show the approximating function on the diagram or not (show the equation on the diagram parameter);
Whether to place the value of the standard deviation on the diagram or not (the parameter put the value of the approximation reliability on the diagram).
Let us choose a polynomial of the second degree as an approximating dependence (Fig. 11) and derive an equation describing this polynomial on the graph (Fig. 12). The resulting diagram is shown in fig. 13.
Similarly, with trend lines you can choose the parameters of such dependencies as
linear y=a∙x+b,
logarithmic y=a ln(x)+b,
exponential y=a∙eb,
power y=a x b,
polynomial y=a∙x 2 +b∙x+c, y=a∙x 3 +b∙x 2 +c∙x+d and so on, up to and including the 6th degree polynomial,
Linear filtering.
4.3. Using the analysis of options tool: Finding a solution.
Of considerable interest is the implementation in MS Excel of the selection of parameters of the functional dependence by the least squares method using the option analysis tool: Search for a solution. This technique allows you to choose the parameters of a function of any kind. Let's consider this possibility on the example of the following problem.
EXAMPLE 3. As a result of the experiment, the dependence z(t) presented in the table
| 0,66 | 0,9 | 1,17 | 1,47 | 1,7 | 1,74 | 2,08 | 2,63 | 3,12 |
| 38,9 | 68,8 | 64,4 | 66,5 | 64,95 | 59,36 | 82,6 | 90,63 | 113,5 |
Select dependency coefficients Z(t)=At 4 +Bt 3 +Ct 2 +Dt+K by the least squares method.
This problem is equivalent to the problem of finding the minimum of a function of five variables
Consider the process of solving the optimization problem (Fig. 14).
Let the values BUT, AT, FROM, D and To stored in cells A7:E7. Calculate the theoretical values of the function Z(t)=At4+Bt3+Ct2+Dt+K for given t(B2:J2). To do this, in the cell B4 enter the value of the function at the first point (cell B2):
B4=$A$7*B2^4+$B$7*B2^3+$C$7*B2^2+$D$7*B2+$E$7.
Copy this formula into the range С4:J4 and get the expected value of the function at points, the abscissas of which are stored in cells B2:J2.
To cell B5 we introduce a formula that calculates the square of the difference between the experimental and calculated points:
B5=(B4-B3)^2,
and copy it to the range С5:J5. In a cell F7 we will store the total quadratic error (10). To do this, we introduce the formula:
F7 = SUM(B5:J5).
Let's use the command Service®Search for a solution and solve the optimization problem without constraints. Fill in the appropriate input fields in the dialog box shown in Fig. 14 and press the button Run. If a solution is found, the window shown in Fig. fifteen.
The result of the decision block will be the output to the cells A7:E7parameter values functions Z(t)=At4+Bt3+Ct2+Dt+K. In cells B4:J4 we get expected function value at starting points. In a cell F7 will be kept total squared error.
You can display the experimental points and the fitted line in the same graphic area if you select the range B2:J4, call Chart Wizard, and then format the appearance of the resulting graphs.
Rice. 17 displays the MS Excel worksheet after the calculations have been made.
4.1. Using built-in functions
calculation regression coefficients carried out using the function
LINEST(Values_y; Values_x; Konst; statistics),
Values_y- array of y values,
Values_x- optional array of values x if array X omitted, it is assumed that this is an array (1;2;3;...) of the same size as Values_y,
Konst- a boolean value that indicates whether the constant is required b was equal to 0. If Konst has the meaning TRUE or omitted, then b calculated in the usual way. If the argument Konst is FALSE, then b is assumed to be 0 and the values a are chosen so that the relation y=ax.
Statistics- a boolean value that indicates whether additional regression statistics are required to be returned. If the argument Statistics has the meaning TRUE, then the function LINEST returns additional regression statistics. If the argument Statistics has the meaning FALSE or omitted, then the function LINEST returns only the coefficient a and permanent b.
It must be remembered that the result of the functions LINEST() is a set of values - an array.
For calculation correlation coefficient function is used
CORREL(Array1;Array2),
returning the values of the correlation coefficient, where Array1- array of values y, Array2- array of values x. Array1 and Array2 must be the same size.
EXAMPLE 1. Addiction y(x) is presented in the table. Build regression line and calculate correlation coefficient.
| y | 0.5 | 1.5 | 2.5 | 3.5 | |||||
| x | 2.39 | 2.81 | 3.25 | 3.75 | 4.11 | 4.45 | 4.85 | 5.25 |
Let's enter a table of values into MS Excel sheet and build a scatter plot. The worksheet will take the form shown in Fig. 2.
In order to calculate the values of the regression coefficients a and b select cells A7:B7, let's turn to the function wizard and in the category Statistical choose a function LINEST. Fill in the dialog box that appears as shown in Fig. 3 and press OK.

As a result, the calculated value will appear only in the cell A6(Fig. 4). For a value to appear in a cell B6 you need to enter edit mode (key F2) and then press the key combination CTRL+SHIFT+ENTER.
To calculate the value of the correlation coefficient per cell C6 the following formula was introduced:
C7=CORREL(B3:J3;B2:J2).

Knowing the regression coefficients a and b calculate the values of the function y=ax+b for given x. To do this, we introduce the formula
B5=$A$7*B2+$B$7
and copy it to the range С5:J5(Fig. 5).

Let's plot the regression line on the diagram. Select the experimental points on the chart, right-click and select the command Initial data. In the dialog box that appears (Fig. 5), select the tab Row and click on the button Add. Fill in the input fields, as shown in Fig. 6 and press the button OK. A regression line will be added to the experimental data plot. By default, its graph will be displayed as dots not connected by smoothing lines.

 Rice. 6
Rice. 6
To change the appearance of the regression line, perform the following steps. Right-click on the points depicting the line graph, select the command Chart type and set the type of scatter plot, as shown in Fig. 7.
The line type, color and thickness can be changed as follows. Select the line on the diagram, press the right mouse button and select the command in the context menu Data Series Format… Next, make settings, for example, as shown in Fig. eight.

As a result of all the transformations, we get a graph of experimental data and a regression line in one graphic area (Fig. 9).

4.2. Using a trend line.
The construction of various approximating dependencies in MS Excel is implemented as a chart property - trend line.
EXAMPLE 2. As a result of the experiment, some tabular dependence was determined.
| 0.15 | 0.16 | 0.17 | 0.18 | 0.19 | 0.20 |
| 4.4817 | 4.4930 | 5.4739 | 6.0496 | 6.6859 | 7.3891 |
Select and build an approximating dependence. Build graphs of tabular and fitted analytical dependencies.
The solution of the problem can be divided into the following stages: input of initial data, construction of a scatter plot and addition of a trend line to this plot.
Let's consider this process in detail. Let's enter the initial data into the worksheet and plot the experimental data. Next, select the experimental points on the chart, right-click and use the command Add l trend line(Fig. 10).

The dialog box that appears allows you to build an approximating dependence.
The first tab (Fig. 11) of this window indicates the type of approximating dependence.
The second one (Fig. 12) defines the construction parameters:
the name of the approximating dependence;
Forecast forward (backward) on n units (this parameter determines how many units forward (backward) it is necessary to extend the trend line);
whether to show the point of intersection of the curve with the line y=const;
whether to show the approximating function on the diagram or not (show the equation on the diagram parameter);
Whether to place the value of the standard deviation on the diagram or not (the parameter put the value of the approximation reliability on the diagram).


Let us choose a polynomial of the second degree as an approximating dependence (Fig. 11) and derive an equation describing this polynomial on the graph (Fig. 12). The resulting diagram is shown in fig. 13.

Similarly, with trend lines you can choose the parameters of such dependencies as
linear y=a∙x+b,
logarithmic y=a ln(x)+b,
exponential y=a∙eb,
power y=a x b,
polynomial y=a∙x 2 +b∙x+c, y=a∙x 3 +b∙x 2 +c∙x+d and so on, up to and including the 6th degree polynomial,
Linear filtering.
4.3. Using the Decider
Of considerable interest is the implementation in MS Excel of the selection of parameters by the least squares method using a decision block. This technique allows you to choose the parameters of a function of any kind. Let's consider this possibility on the example of the following problem.
EXAMPLE 3. As a result of the experiment, the dependence z(t) presented in the table
| 0,66 | 0,9 | 1,17 | 1,47 | 1,7 | 1,74 | 2,08 | 2,63 | 3,12 |
| 38,9 | 68,8 | 64,4 | 66,5 | 64,95 | 59,36 | 82,6 | 90,63 | 113,5 |
Select dependency coefficients Z(t)=At 4 +Bt 3 +Ct 2 +Dt+K by the least squares method.
This problem is equivalent to the problem of finding the minimum of a function of five variables
Consider the process of solving the optimization problem (Fig. 14).

Let the values BUT, AT, FROM, D and To stored in cells A7:E7. Calculate the theoretical values of the function Z(t)=At4+Bt3+Ct2+Dt+K for given t(B2:J2). To do this, in the cell B4 enter the value of the function at the first point (cell B2):
B4=$A$7*B2^4+$B$7*B2^3+$C$7*B2^2+$D$7*B2+$E$7.
Copy this formula into the range С4:J4 and get the expected value of the function at points, the abscissas of which are stored in cells B2:J2.
To cell B5 we introduce a formula that calculates the square of the difference between the experimental and calculated points:
B5=(B4-B3)^2,
and copy it to the range С5:J5. In a cell F7 we will store the total quadratic error (10). To do this, we introduce the formula:
F7 = SUM(B5:J5).
Let's use the command Service®Search for a solution and solve the optimization problem without constraints. Fill in the appropriate input fields in the dialog box shown in Fig. 14 and press the button Run. If a solution is found, the window shown in Fig. fifteen.
The result of the decision block will be the output to the cells A7:E7parameter values functions Z(t)=At4+Bt3+Ct2+Dt+K. In cells B4:J4 we get expected function value at starting points. In a cell F7 will be kept total squared error.
You can display the experimental points and the fitted line in the same graphic area if you select the range B2:J4, call Chart Wizard, and then format the appearance of the resulting graphs.
Rice. 17 displays the MS Excel worksheet after the calculations have been made.



5. REFERENCES
1. Alekseev E.R., Chesnokova O.V., Solving problems of computational mathematics in the packages Mathcad12, MATLAB7, Maple9. – NT Press, 2006.–596s. :ill. – (Tutorial)
2. Alekseev E.R., Chesnokova O.V., E.A. Rudchenko, Scilab, solving engineering and mathematical problems. –M., BINOM, 2008.–260s.
3. I. S. Berezin and N. P. Zhidkov, Methods of Computation, Moscow: Nauka, 1966.
4. Garnaev A.Yu., The use of MS EXCEL and VBA in economics and finance. - St. Petersburg: BHV - Petersburg, 1999.-332p.
5. B. P. Demidovich, I. A. Maron, and V. Z. Shuvalova, Numerical Methods of Analysis.–M.: Nauka, 1967.–368p.
6. Korn G., Korn T., Handbook of mathematics for scientists and engineers.–M., 1970, 720p.
7. Alekseev E.R., Chesnokova O.V. Guidelines for performing laboratory work in MS EXCEL. For students of all specialties. Donetsk, DonNTU, 2004. 112 p.
Well, at work they reported to the inspection, the article was written at home for the conference - now you can write in the blog. While I was processing my data, I realized that I could not help but write about a very cool and necessary add-in in Excel, which is called . So the article will be devoted to this particular add-in, and I will tell you about it using an example of using least squares method(LSM) to search for unknown coefficients of the equation in the description of experimental data.
How to enable the add-on "search for a solution"
First, let's figure out how to enable this add-on.
1. Go to the "File" menu and select "Excel Options"
2. In the window that appears, select "Search for a solution" and click "go".

3. In the next window, put a checkmark in front of the "search for a solution" item and click "OK".

4. The add-in is activated - now it can be found in the "Data" menu item.
Least square method
Now briefly about least squares method (LSM) and where it can be applied.
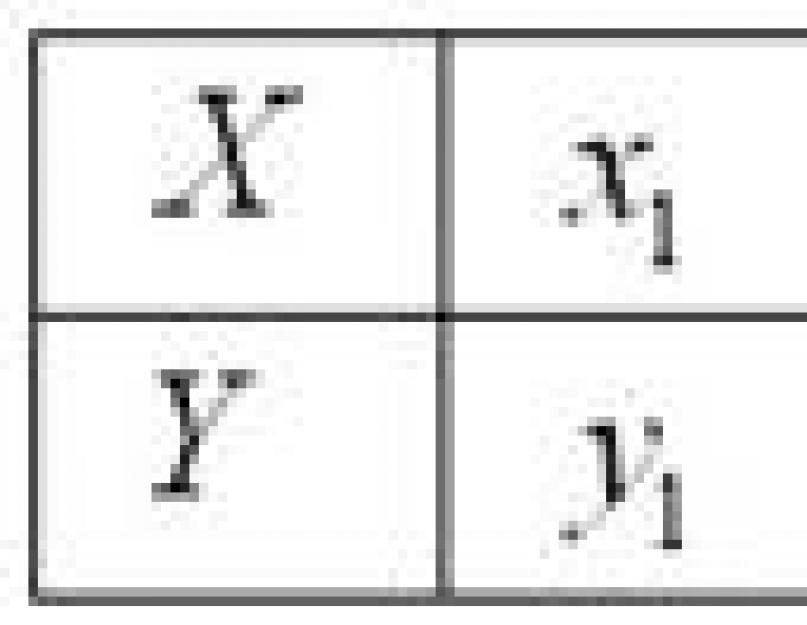
Let's say we have a data set after we have performed some experiment where we studied the effects of the X value on the Y value.
We want to describe this influence mathematically, so that later we can use this formula and know that if we change the value of X by so much, we will get the value of Y such and such ...
Let's take a super-simple example (see picture).

No brainer that the points are located one after another as if in a straight line, and therefore we safely assume that our dependence is described by a linear function y=kx+b. At the same time, we are sure that when X is equal to zero, the value of Y is also equal to zero. This means that the function describing the dependence will be even simpler: y=kx (remember the school curriculum).
In general, we have to find the coefficient k. This is what we will do with MNC using the "search for a solution" add-on.
The method is to (here - attention: you need to think about it) the sum of the squared differences between the experimentally obtained and the corresponding calculated values was minimal. That is, when X1=1 the actual measured value Y1=4.6, and the calculated y1=f (x1) is 4, the square of the difference will be (y1-Y1)^2=(4-4.6)^2=0.36 . Same with the following: when X2=2, the actual measured value Y2=8.1, and the calculated y2 is 8, the square of the difference will be (y2-Y2)^2=(8-8.1)^2=0.01. And the sum of all these squares should be as small as possible.

So, let's start training on the use of LSM and Excel add-ins "search for solution" .
Application of add-in find solution
1. If you didn’t enable the “search for a solution” add-on, then return to step How to enable the add-on "search for a solution" and enable 🙂
2. In cell A1, enter the value "1". This unit will be the first approximation to the real value of the coefficient (k) of our functional dependence y=kx.
3. In column B we have the values of the parameter X, in column C - the values of the parameter Y. In the cells of column D we enter the formula: “coefficient k multiplied by the value X”. For example, in cell D1, enter "=A1*B1", in cell D2, enter "=A1*B2", and so on.

4. We believe that the coefficient k is equal to one and the function f (x) \u003d y \u003d 1 * x is the first approximation to our solution. We can calculate the sum of squared differences between the measured values of Y and those calculated using the formula y=1*x. We can do all this manually by driving the appropriate cell references into the formula: "=(D2-C2)^2+(D3-C3)^2+(D4-C4)^2... etc. In the end we are mistaken and understand that we have lost a lot of time.In Excel, for calculating the sum of squared differences, there is a special formula, "SUMQDIFF", which will do everything for us.Let's enter it in cell A2 and set the initial data: the range of measured values Y (column C) and range of calculated Y values (column D).

4. The sum of the differences of the squares was calculated - now go to the "Data" tab and select "Search for a solution".
5. In the menu that appears, select cell A1 as the cell to be changed (the one with the coefficient k).
6. As the target, select cell A2 and set the condition "set equal to the minimum value." Remember that this is the cell where we calculate the sum of the squared differences between the calculated and measured values, and this amount should be minimal. We press "execute".

7. Coefficient k is selected. Now it can be seen that the calculated values are now very close to the measured ones.
P.S.
In general, of course, for the approximation of experimental data in Excel, there are special tools that allow you to describe the data using a linear, exponential, power and polynomial function, so you can often do without add-ons "Search for a solution". I talked about all these methods of approximation in my article, so if you are interested, take a look. But when it comes to some exotic function with one unknown coefficient or optimization problems, then here superstructure as well as possible.
Add-in "search for a solution" can be used for other tasks, the main thing is to understand the essence: there is a cell where we select a value, and there is a target cell in which a condition is set for selecting an unknown parameter.
That's all! In the next article I will tell a fairy tale about a vacation, so in order not to miss the release of the article,


